
博弈理论
基本概念:囚徒困境
博弈论中的相互作用通常是根据明确的定义来建模的游戏在两个或多个之间球员.为了说明这一点,考虑下面这个简单的游戏,通常被称为囚徒困境,在Alice和Bob之间进行。
囚徒困境。警察逮捕了两名罪犯,并在不同的房间里审问他们,因此他们无法相互交流。他们各自提供以下交易:
- 如果Alice告发Bob, Alice就会被释放,而Bob会在监狱里呆三年。(Alice叛变,Bob合作)
- 类似地,如果鲍勃告发了爱丽丝,鲍勃就会被释放,而爱丽丝则要在监狱里呆三年。(Alice配合,Bob背叛)
- 如果他们都不告发对方,那么他们都要在监狱里待一年。(相互合作)
- 如果他们都互相告密,那他们都会在监狱里待两年。(共同背叛)
在囚徒困境中,爱丽丝和鲍勃各自选择一种策略,缺陷或合作,总共有四种可能的组合,每一种组合都对应一个结果,或回报.因此,我们可以得出以下结论支付矩阵这本书说明了每种策略组合的收益。(在下图中,有序对 表示Alice和Bob消费 而且 分别被判入狱数年。)
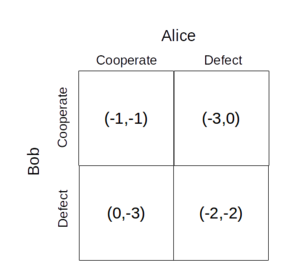
看看这个游戏为什么叫"囚犯游戏两难的境地,想想每个参与人会选择什么策略。假设每个囚犯的目标仅仅是尽量减少自己在监狱里的时间,并且他或她不知道其他玩家可能会选择什么策略。
从Bob的角度考虑游戏。从收益矩阵中,很明显,无论爱丽丝选择什么策略,鲍勃都会通过叛逃来最小化他在监狱里度过的时间。如果爱丽丝合作,鲍勃就会叛逃(因为他不用在监狱里待一年,而是不用待一段时间);如果爱丽丝叛变了,鲍勃也应该叛变(因为他将在监狱里呆两年而不是三年)。这个游戏对两个玩家都是对称的,从爱丽丝的角度来看也是一样的,她也应该叛变。
因此,如果双方都是理性的也就是说,如果他们希望最大化自己的收益,游戏就会导致双方的背叛。据说相互背叛是游戏的纳什均衡这是一套没有参与人能够通过改变策略来提高收益的策略。(一般来说,一个博弈可能有多个纳什均衡,但囚徒困境只有一个。)
从某种意义上说,相互背叛并不能使参与人的收益最大化,在这种情况下,可以说纳什均衡不是非常高效。(具体地说,帕累托有效的).纳什均衡并不是有效的解决方案,这是囚徒困境的核心。

有两个纳什均衡的一个例子是猎鹿.
猎鹿。两个猎人,爱丽丝和鲍勃,坐着等待一头牡鹿,这将为两个猎人在被击倒后提供重要的食物。兔子也出现了,如果它们被杀死,就会喂给一个猎人。雄鹿就在附近,最终会进入猎人弓箭的射程;然而,如果野兔被猎杀,猎人就会扰乱森林,把鹿吓跑。两个猎人都能捕到野兔。
- 如果只有爱丽丝去猎杀兔子,爱丽丝就能得到一天的食物,而鲍勃就会挨饿。(Alice叛变,Bob合作)
- 类似地,如果只有鲍勃去猎杀兔子,鲍勃获得了一天的食物,而爱丽丝会挨饿。(Alice配合,Bob背叛)
- 如果两个猎人都猎杀这只鹿,这只鹿为一个人提供了四天的食物,那么在分配战利品后,每个猎人都能获得足够两天的食物。(相互合作)
- 如果他们都去抓野兔,那么他们都能得到一天的食物。(共同背叛)
猎鹿与囚徒困境的不同之处在于存在两个纳什均衡:两个猎人都可能背叛(猎野兔)或合作(猎鹿)。通过合作,双方都能获得最优结果。很明显,完全理性的玩家都会推断对方会猎杀鹿,玩家会默认相互合作。
然而,在现实世界中,玩家可能是这样的风险规避:他或她可能会预料到另一个棋手不能打出最佳走法,从而反过来叛变。例如,想象一下,当其他玩家背叛时,合作的结果是饥饿和死亡(即,高度负收益)。雄鹿可能会比野兔带来更好的回报,但双方都不能容忍对方选择背叛的风险。
迭代的游戏
然而,在现实中,当人类测试对象被要求扮演囚徒困境时,相互合作往往会产生。这是否表明人类是非理性的呢?也许吧,但我们不难简单地认为,上面提出的简单模型无法捕捉现实世界问题的所有维度。首先,人类玩家可能不会从简单的回报矩阵来看待囚徒困境。例如,鲍勃可能出于荣誉感决定不告发狱友。
即便如此,对囚徒困境中所描述的基本情景进行简单的阐述,也有助于解释各种各样的行为。想想当人们玩游戏时会发生什么重复囚徒困境假设Alice和Bob玩囚徒困境 连续几次。在迭代游戏的情况下,策略不再是独立于其他玩家的策略而选择的单个行动,而是一种策略序列的动作。每一步都可以在考虑到前一步的情况下进行选择:例如,当且仅当Alice在前一步中合作时,Bob可以选择合作。
例如,示例策略可能包括以下内容:
- 总是合作:每一步都要合作。
- 总是缺陷:每一步都要叛变。
- 随机:的概率 ,缺陷;否则,合作。
- 针锋相对的:如果对手在前一步中合作,则合作;否则,缺陷。合作迈出第一步。
与 固定,简单逆向归纳法这一论证足以说明纳什均衡总是有缺陷的。最后一步与非迭代囚徒困境相同:显然,一个人应该在 因为没有下一步棋了。鉴于相互的叛变会被打的 这一招,再合理也要打为之 移动。由此可见,每走一步,双方都应该叛变。
然而,如果 是由概率决定的(游戏邦注:也许游戏的每一步都有一定的结束概率)还是无限的,那么“最优”策略就不那么清楚了:所有可能策略的集合,即战略空间它非常大。
不过,通过模拟分析反复的囚徒困境,还是可以取得一些进展的。1980年,罗伯特·阿克塞尔罗德(Robert Axelrod)为一个反复的囚徒困境锦标赛(结局按概率确定)征集参赛作品。这些意见书来自业余爱好者和学者,以计算机程序的形式指明了策略。在14名参赛者中,阿纳托尔·拉波波特(Anatol Rapoport)明显胜出,他提出了迄今为止最简单的策略:以牙还牙。紧随他的比赛所获得的关注,阿克塞尔罗德进行了第二轮比赛,吸引了60多份参赛作品,其中一些相当复杂。胜利者再次是拉波波特,他又一次以牙还牙。[1]
此后,人们使用了更复杂的方法来分析迭代囚徒困境和其他迭代游戏,但阿克塞尔罗德的竞赛仍然提供了一些启发式的见解,让人们了解哪些策略可能更成功。事实证明,试图利用“友好的”合作策略是相当困难的,因为当与以牙还牙的策略相匹配时,这样做会带来严重的惩罚。以牙还牙在高度合作和高度缺陷的战略中都表现得相当好,因为它会以同样的方式回报。尽管这种针锋相对的策略在对抗高度合作的策略时效果不如高度缺陷的策略,但在对抗其他“类似针锋相对”的策略时效果很好。
以牙还牙的强大特性为合作的演变提供了一种貌似合理的机制。在进化生物学或社会科学中,许多情况并不涉及单发的囚徒困境游戏,这种游戏往往会导致不合作,而是反复的互动。这种互动可能是类似于以牙还牙的互惠战略所产生的合作的基础。
更多类型的游戏
囚徒困境只是经常被研究的众多游戏之一。游戏不需要只在两名玩家之间进行,动作不需要同时进行,甚至不需要确定。
因为“游戏”的正式构成可以相当广泛,这有助于根据不同属性对游戏进行分类。
一个游戏的玩家据说有完美的信息如果所有玩家都知道每个玩家的行动顺序。一个组合游戏是一个确定的所有参与者都拥有完全信息的游戏。例如国际象棋、井字游戏和尼姆.组合博弈被称为解决了当最优策略(如果存在的话)是已知的。
游戏被称为游戏零和游戏如果所有参与人的收益总和是常数(包括零)。从本质上讲,没有一个参与者能够在不降低其他参与者的收益的情况下获得更高的收益。
一个同时游戏在一个游戏中,所有玩家都同时有效地移动,而在一个游戏中,所有玩家的移动都是不同时的顺序游戏.国际象棋和井字游戏是连续的。囚徒困境的基本形式是同时的,尽管人们当然可以制定一种迭代囚徒困境的形式,其中的动作是交错的(这将是连续的)。对于后一种情况,使用决策树其中,策略空间和收益被画在一个分枝树上,列举所有可能的移动序列。
 表示
表示
游戏也可能是不对称.而在囚徒困境中,双方都有相同的行动选择,也就是对称的在美国,也有许多例子表明情况并非如此。在最后通牒游戏,一个人被要求为他自己和另一个玩家分配一大笔钱。第二个玩家可以选择接受或拒绝给他或她的那部分。
参考文献
阿克塞尔罗德,R。"囚徒困境中更有效的选择"冲突解决杂志24: 379-403(1980)。