
囚犯的困境
纳什Equilbrium和帕累托最优
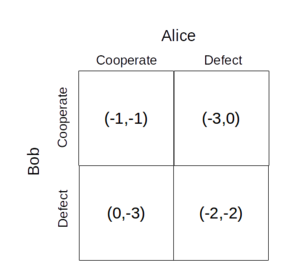
为了确定游戏的结果,我们需要一种方法来描述每个玩家如何做出决定。每个玩家都能选择将使他们最高收益的动作,假设其他玩家的动作是固定的。这是描述囚犯困境的理想选择,因为每个囚犯必须在没有与另一个沟通的情况下做出决定。
鲍勃的原因如此:
- 如果Alice决定合作,那我花1年的监禁,如果我合作,并0,如果我背叛,所以我应该缺陷。
- 如果Alice决定缺陷,然后我花了在监狱里超过3年我合作,2,如果我背叛,所以我应该缺陷。
爱丽丝也方面的原因,同样的方式。这种情况是一个纳什均衡。它是最佳的缺陷,因为在任何情况下,最佳的“我”的最佳解决方案就是缺陷。
然而,这种平衡并不捕获“最好”的结果的概念。这两名球员的合作是双方球员更好。帕累托效率的结果是最好的

“级数”和Newcomb的问题
因为其结果是更好地为双方球员,如果他们两个比他们两个缺陷合作,很多人尝试开发的决策,以确保玩家们将合作的理论。
侯世国提出所谓的解决方案“superrationality。”Superrationality假设玩家玩自己过不去的副本。如果他们是真正的副本,那么它是不可能的一名球员,而其他缺陷合作。唯一的选择是既合作,既背叛,两者的合作是最好的之间。
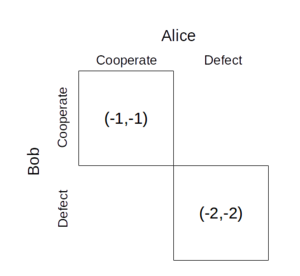
这种思维方式是基础永恒的决策理论,替代代表所描述的决策标准形式的替代方案[1]。在永恒的决策理论,而不是选择一个动作假设每个人的行为都是固定的,代理人选择的行动假设相同的所有其他代理必须选择同样的动作。这种想法也被用来解决纽康的悖论。在这个问题,可以预测你的动作的机器人给你两个盒子,这是充满了金钱这取决于机器人预测你会做。如果机器人能够预测你的行为完美,这就像你对自己的副本一起玩一样。此设置与上级囚犯的困境相同。
迭代囚犯的困境
在标准的囚徒困境中,玩家只互相对战一次。然而,在现实生活中的游戏中,玩家通常会互相对战多次。他们需要考虑什么其他球员将在未来几轮基础上,在这一轮会发生什么事。例如,你可能会认为这是合理的,从偷
在双方球员知道的情况下恰好有 回合,合理的解决可以通过发现K级思维。考虑到这一点 圆形的。球员的理由是因为未来没有更多轮次,没有理由合作,所以她缺陷。同样,球员2理由应该缺陷。但是 圆形的推理是一样的。他们都知道,他们将在这两个缺陷 无论如何,都没有理由没有缺勤 圆形的。通过归纳,他们俩总是缺陷。和以前一样,合理的解决方案是为双方球员不是总合作严格更糟。
这意味着它更容易获得代理时,他们对比赛的样子在未来的信息较少合作。
这是非常困难的一个严格的方式是什么策略的重复囚徒困境最好的说法,特别是因为一个战略的成功取决于什么样的战略其他玩家使用。弄明白,最好的办法是代表使用的策略代理,然后让他们在锦标赛中互相对战写程序(或“机器人”)。
最简单的两种策略是:[2]
- 合作:CooperateBot总是合作
- 缺陷:DefectBot总是缺陷
自缺陷以来总是缺陷,不管你做什么,然后对DefectBot玩的时候最好的选择始终是缺陷。当对DefectBot玩,它可能是有意义的有这样一个策略
- ReasonableBot:对,否则DefectBot ReasonableBot缺陷,但协作
不幸的是,这使得一个打开计数器策略:
- trollbot.:TrollBot协作与任何人与谁合作DefectBot,和缺陷对任何人谁反对DefectBot缺陷
如果机器人对阵99个缺陷和1个Trollbot的池,那么它仍然值得
迭代囚犯困境中最常见的策略是山雀 - tat。一个TitForTatBot将在第一轮它起着合作
在进化生物学,针锋相对针锋相对策略来解释发展互惠利他主义在物种中。尽管每个单独的基因都是自私的(即,通过缺陷的任何给定点始终会有更高的收益),但它可以整体对生物来互相帮助,从而避免永远缺陷的不利均衡互相反对。在进化迭代囚犯的困境方案锦标赛中,每个机器人都以与收到的收益量成比例的比例复制。这种模仿生物学,其中成功消耗另一种动物的动物比一个人更容易繁殖,而且更容易复制,而且比花费能量打击另一种动物的动物。
参考
- Yudkowsky,E.永恒的决策理论。从...获得https://intelligence.org/files/tdt.pdf.
- LaVictoire,P.在囚徒困境强大的合作。从...获得http://lesswrong.com/lw/hmw/robust_cooperation_in_the_prisoners_dilemma/