
遍历
一个树遍历,也被称为树搜索算法上执行图只包含树边,只访问每个节点一次。这类算法的区别仅仅在于访问每个节点的顺序不同。遍历树的两种经典方法是广度优先搜索(bfs),其中节点在同一水平或者在继续到下一层之前访问根的距离;而且深度优先搜索,其中a中的所有节点分支,或者从根到叶的一条固定路径,在传递到下一个分支之前被访问。还有一些方法使用启发式或随机抽样在树中移动,作为加快过程的一种方式。
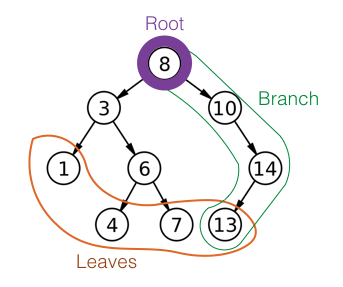 根、树和分支是树数据结构的基本部分。
根、树和分支是树数据结构的基本部分。
注意:二叉树最常用于说明树遍历,但解可以推广到所有树。它还假设左边的节点先于右边的节点,但如果有适当的一致性,这种情况可以逆转。
遍历树
不像一个数组或者是一组被设计成按顺序处理的数字,树并不表示元素的线性配置;相反,处理可以在给定节点或节点的任何子节点上进行。
由于这种类型的算法在向下遍历树时必须选择下一个要处理的节点,因此算法必须记住它没有访问的节点,以便稍后探究它们。为了达到这个目的,算法采用一种堆栈,其中最近存储的节点具有优先级;或者一个队列,其中存储在数组中的第一个项具有最高优先级。这些技术通常使用递归,这允许短数量的指令,或行代码。所使用的特定技术取决于预期的目的,无论是解决问题搜索,分而治之,或图论问题等等。
排队就像一排人,第一个到的人是第一个得到服务的人。这种数据存储技术也被称为FIFO,或先进先出。另一方面,把一堆想象成一堆盘子,最后一个在上面的是第一个被使用的。这也被称为后进先出。

深度优先搜索
深度优先搜索DFS是一种策略,它沿着一个分支一直走下去,直到到达一个叶子,处理该分支,然后移动到另一个分支。这种类型的算法通常使用堆栈来跟踪访问的节点,因为最后一个看到的节点就是下一个要访问的节点,其余的节点被存储起来供以后访问。
伪代码[3]
初始化一个用于存储节点s的空堆栈,对于每个顶点u,定义u.visited为false。将根节点(第一个被访问的节点)推到S上,当S不为空时:弹出S, u中的第一个元素。如果u.visited = false,那么:u.visited = true对于u的每个未访问的邻居w:当所有节点都访问过时,将w推入S。没有Recrusion的Python实现
defdepht_first_search(图):参观了,堆栈=集(),[根]而堆栈:顶点=堆栈.流行()如果顶点不在参观了:参观了.添加(顶点)堆栈.扩展(图[顶点]-参观了)返回参观了
DFS还可以使用递归实现,这大大减少了代码行数。
Python使用递归实现
defdepth_first_search_recursive(图,开始,参观了=没有一个):如果参观了是没有一个:参观了=集()参观了.添加(开始)为下一个在图[开始]-参观了:depth_first_search_recursive(图,下一个,参观了)返回参观了
为了跟踪边而不是顶点,通常需要修改算法,因为每条边都描述了每一端的节点。当处理完每个节点后试图重构遍历树时,这很有用。对于森林或一组树,该算法可以扩展为包含一个外部循环,遍历所有树,以便处理每个节点。
 动画深度优先搜索算法[4]
动画深度优先搜索算法[4]
实现DFS有三种不同的策略:预购,按次序的,后序.
预购DFS的工作原理是访问当前节点,然后依次向左移动,直到到达一个叶节点,在到达叶节点的过程中访问每个节点。一旦节点左侧没有更多的子节点,则访问右侧的子节点。这是最标准的DFS算法。
而不是在遍历树时访问每个节点按次序的算法找到树中最左边的节点,访问该节点,然后访问该节点的父节点。然后,它转到右边的子节点,找到树中最左边的下一个节点进行访问。
一个后序策略的工作原理是访问树中最左边的叶节点,然后向上到父节点,向下到同一分支中最左边的第二个叶节点,以此类推,直到父节点成为分支中最后一个要访问的节点。这种算法优先处理叶节点而不是根节点,以防目标位于树的末端。

深度优先搜索算法被广泛应用于图论:当发现最短的路径比如,检测一个循环,寻找连接的组件,对一棵树进行排序,或者在迷宫中找到出口或目标。
广度优先搜索
广度优先搜索,或BFS,是树遍历技术中DFS的对应物。它是一种使用队列作为数据数组遍历树的搜索算法,其中的元素以先进先出(FIFO)机制访问。这种策略也被称为level-order遍历,即在进入下一个关卡之前访问一个关卡上的所有节点。
BFS的伪代码与DFS完全相同,除了a队列而不是堆栈来存储未访问的节点。这将改变被访问节点的顺序,因为按时间顺序,第一个被存储的节点具有下一个被访问的最高优先级。换句话说,BFS先访问节点的所有邻居,然后再访问邻居的邻居。
伪代码[3]
初始化一个用于存储节点s的空队列,对于每个顶点u,定义u.visited为false。将根节点(第一个被访问的节点)推到S上,当S不为空时:弹出S: u中的最后一个元素。如果u.visited = false,则:u.visited = true对于u的每个未访问的邻居w:当所有节点都访问过时,将w推入S。Python实现
defbreadth_first_search(图):参观了,队列=集(),[根]而队列:顶点=队列.流行(0)如果顶点不在参观了:参观了.添加(顶点)队列.扩展(图[顶点]-参观了)返回参观了
 动画宽度优先搜索算法。[5]
动画宽度优先搜索算法。[5]
选择遍历技术
其他算法已经开发出来,可以在不使用BFS或DFS的情况下遍历树。这些算法包括蒙特卡罗树搜索,它利用随机抽样横穿树;还有很多其他的图搜索算法它试图利用附加信息快速有效地找到给定的目的地。其中包括爬山算法,束搜索算法,分支定界算法,一个*算法,这些都用到了启发式或者其他图形的洞察,来确定下一个遍历的最佳步骤。
另一个树遍历问题的例子是无限的树,其中实际上有无限数量的节点。这些类型的树代表着巨大的问题复杂的空间例如下棋的计算机或最近开发的围棋计算机。这些问题给简单的DFS和BFS实现带来了困难,因为算法可能永远不会访问给定使用DFS的实现的分支的末尾,或者可能永远不会访问给定使用BFS的实现的每个分支。
中的更多树遍历应用程序计算机科学,请参考康尼锡的无穷引理,旅行推销员的问题,切尼的算法,或福特Fulkerson的算法.
参考文献
- 石汤,J。减少。重用。“回收利用”。3r如何帮你洗碗.从检索http://thestonesoup.com/blog/2011/01/reduce-reuse-recycle-how-the-3rs-can-help-you-with-the-washing-up/
- Pixabay,。行,人.从检索https://pixabay.com/static/uploads/photo/2014/08/31/00/58/people-431943_960_720.jpg
- 堆,D。深度优先搜索(DFS).2002年12月16日,从http://www.cs.toronto.edu/~heap/270F02/node36.html
- 维基,M。Depth-First-Search.gif.检索自2016年7月15日https://commons.wikimedia.org/wiki/File:Depth-First-Search.gif
- 维基,M。文件:Depth-First-Search.gif.从检索https://upload.wikimedia.org/wikipedia/commons/5/5d/Breadth-First-Search-Algorithm.gif)
{kind=link}
{kind=link}
){kind=link}