
霍夫曼编码gydF4y2Ba
霍夫曼编码gydF4y2Ba是一种有效的压缩数据而不丢失信息的方法。在计算机科学中,信息被编码为位1和位0。gydF4y2Ba位字符串的gydF4y2Ba编码信息,告诉计算机执行哪些指令。电子游戏、照片、电影等等都被编码为计算机中的比特串。计算机每秒执行数十亿条指令,而一款电子游戏可以包含数十亿比特的数据。很容易看出为什么高效和明确的信息编码是计算机科学的一个感兴趣的主题。gydF4y2Ba
霍夫曼编码通过分析消息中某些符号出现的频率,提供了一种高效、明确的代码。经常出现的符号将被编码为短位字符串,而不经常使用的符号将被编码为长字符串。由于符号的频率随消息的不同而不同,因此没有一种霍夫曼编码适用于所有消息。这意味着用于发送消息X的霍夫曼编码可能与用于发送消息y的霍夫曼编码不同。有一种算法用于根据特定消息中符号的频率为给定消息生成霍夫曼编码。gydF4y2Ba
霍夫曼编码的工作原理是使用频率排序gydF4y2Ba二叉树gydF4y2Ba编码符号。gydF4y2Ba

内容gydF4y2Ba
信息编码gydF4y2Ba
在gydF4y2Ba信息理论gydF4y2Ba,其目标通常是用尽可能少的位来传输信息,以使每种编码都是明确的。例如,要用尽可能少的比特编码A、B、C和D,每个字母可以被编码为“1”。然而,使用这种编码,消息“1111”可能意味着“ABCD”或“AAAA”——这是模糊的。gydF4y2Ba
编码可以是定长或变长。gydF4y2Ba
一个gydF4y2Ba定长编码gydF4y2Ba就是每个符号的编码都有相同的位数。例如:gydF4y2Ba
一个gydF4y2Ba 00gydF4y2Ba BgydF4y2Ba 01gydF4y2Ba CgydF4y2Ba 10gydF4y2Ba DgydF4y2Ba 11gydF4y2Ba 一个gydF4y2Ba变长编码gydF4y2Ba可以用不同的比特数编码符号。例如:gydF4y2Ba
一个gydF4y2Ba 000gydF4y2Ba BgydF4y2Ba 1gydF4y2Ba CgydF4y2Ba 110gydF4y2Ba DgydF4y2Ba 1111gydF4y2Ba
解释为什么下面的编码方案是一个糟糕的编码。gydF4y2Ba
一个gydF4y2Ba BgydF4y2Ba CgydF4y2Ba DgydF4y2Ba 0gydF4y2Ba 1gydF4y2Ba 11gydF4y2Ba 10gydF4y2Ba
让我们尝试一些编码:gydF4y2Ba
- 编写消息BAC的二进制编码。gydF4y2Ba 1011gydF4y2Ba
- 编写消息DC的二进制编码。gydF4y2Ba 1011gydF4y2Ba
- 编写消息DDC的二进制编码。gydF4y2Ba 101011gydF4y2Ba
- 编写消息BADBB的二进制编码。gydF4y2Ba 101011gydF4y2Ba
从上面的消息编码可以看出,在某些情况下,相同的二进制字符串会编码不同的消息。这种编码方案是模糊的,因为在我们对一条消息进行编码后,它的二进制表示并不只针对该消息。例如,在上面的编码中,“BB”被编码为“11”,但“11”也是“C”的编码。gydF4y2Ba
下面的编码是明确的,但效率低,因为存在更短的(仍然是明确的)这些字母的编码。给出一个等价但更短的编码。gydF4y2Ba
一个gydF4y2Ba BgydF4y2Ba CgydF4y2Ba DgydF4y2Ba 0000gydF4y2Ba 0101gydF4y2Ba 1010gydF4y2Ba 1111gydF4y2Ba
每个字母的编码位数都是相同的。因此,我们知道每gydF4y2Ba 字符串中的位将编码一个字母。与上面的例子(使用变长编码)不同,我们不必担心歧义,因为每个字母都有相同长度的唯一二进制赋值。例如,如果B被编码为1,C被编码为11,在看到消息11时,我们无法判断发送者是想发送BB还是C。在上面的固定长度编码中,编码之间不可能有重叠:0000总是被读取为a,而1010总是被读取为C。gydF4y2Ba
然而,这些编码的长度是所需长度的两倍:有冗余信息,因为4位编码只是重复相同的2位编码。gydF4y2Ba
代表gydF4y2Ba 符号,我们需要gydF4y2Ba 位,因为每个位有两个可能的值:1或0。因此,与gydF4y2Ba 我们可以表示比特gydF4y2Ba 不同的符号。gydF4y2Ba
这个问题已经gydF4y2Ba 符号,所以我们只需要gydF4y2Ba 要做到这一点。因此,我们的编码可以如下:gydF4y2Ba
一个gydF4y2Ba BgydF4y2Ba CgydF4y2Ba DgydF4y2Ba 00gydF4y2Ba 01gydF4y2Ba 10gydF4y2Ba 11gydF4y2Ba
需要表示多少位gydF4y2Ba 不同的符号(使用固定长度的编码)?gydF4y2Ba
代表gydF4y2Ba 具有固定长度编码的符号,gydF4y2Ba 比特是必需的,因为每个比特都有两个可能的值:1或0。因此,与gydF4y2Ba 位,gydF4y2Ba 可以表示不同的符号。gydF4y2Ba
霍夫曼编码gydF4y2Ba
霍夫曼编码是一种编码信息的方法,使用可变长度的字符串来表示符号,这取决于符号出现的频率。其理念是,使用频率更高的符号应该更短,而很少出现的符号可以更长。这样,平均而言,编码给定信息所需的比特数将比使用固定长度的编码短。在包含许多稀有符号的消息中,由变长编码产生的字符串可能比由定长编码产生的字符串长。gydF4y2Ba
如上面几节所示,编码方案的明确是很重要的。由于变长编码容易产生歧义,因此必须小心生成避免歧义的方案。霍夫曼编码使用gydF4y2Ba贪婪算法gydF4y2Ba构建一棵优化编码方案的前缀树,使使用频率最高的符号具有最短的编码。描述编码的前缀树确保任何特定符号的代码永远不是表示任何其他符号的位串的前缀。要确定一个符号的二进制赋值,要使树的叶与符号对应,而赋值将是从树的根到该叶的路径。gydF4y2Ba
我们从下面的霍夫曼树中得到什么编码?gydF4y2Ba

| 象征gydF4y2Ba | 编码# 1gydF4y2Ba |
| 一个gydF4y2Ba | 0000gydF4y2Ba |
| BgydF4y2Ba | 01gydF4y2Ba |
| CgydF4y2Ba | 101gydF4y2Ba |
| DgydF4y2Ba | 1gydF4y2Ba |
| EgydF4y2Ba | 0000gydF4y2Ba |
| 象征gydF4y2Ba | 编码# 2gydF4y2Ba |
| 一个gydF4y2Ba | 1gydF4y2Ba |
| BgydF4y2Ba | 01gydF4y2Ba |
| CgydF4y2Ba | 001gydF4y2Ba |
| DgydF4y2Ba | 0001gydF4y2Ba |
| EgydF4y2Ba | 0000gydF4y2Ba |
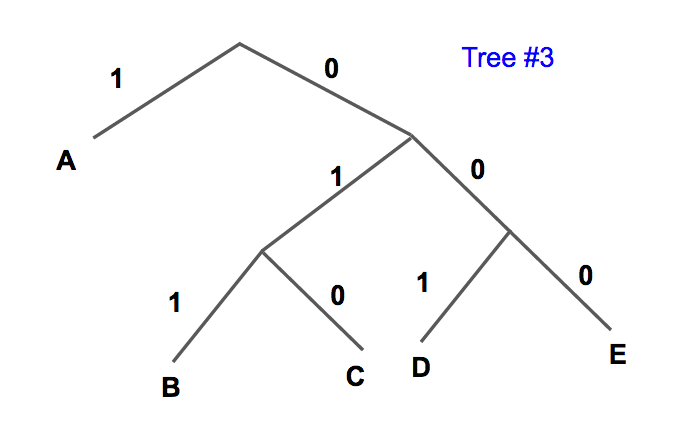
| 象征gydF4y2Ba | 编码# 3gydF4y2Ba |
| 一个gydF4y2Ba | 1gydF4y2Ba |
| BgydF4y2Ba | 1gydF4y2Ba |
| CgydF4y2Ba | 1gydF4y2Ba |
| DgydF4y2Ba | 1gydF4y2Ba |
| EgydF4y2Ba | 0gydF4y2Ba |
霍夫曼编码算法接受有关特定符号出现的频率或概率的信息。它开始从下往上构建前缀树,从列表中概率最小的两个符号开始。它接受这些符号并形成包含它们的子树,然后从列表中删除单个符号。该算法将子树中元素的概率相加,并将子树及其概率添加到列表中。接下来,算法搜索列表并选择概率最小的两个符号或子树。它使用这些来创建一个新的子树,从列表中删除原来的子树/符号,然后将新的子树及其组合概率添加到列表中。这个过程一直重复,直到有一个树,所有的元素都被添加。gydF4y2Ba
给定下面的概率表,创建一个霍夫曼树来编码每个符号。gydF4y2Ba
象征gydF4y2Ba 概率gydF4y2Ba 一个gydF4y2Ba BgydF4y2Ba CgydF4y2Ba DgydF4y2Ba EgydF4y2Ba 概率最小的两个元素是D和e,所以我们创建了子树:gydF4y2Ba
并更新该列表以包含概率为的子树DEgydF4y2Ba
象征gydF4y2Ba 概率gydF4y2Ba 一个gydF4y2Ba BgydF4y2Ba CgydF4y2Ba 德gydF4y2Ba 接下来的两个最小概率是DE和C,所以我们创建了子树:gydF4y2Ba
并更新该列表以包含概率为的子树CDEgydF4y2Ba
象征gydF4y2Ba 概率gydF4y2Ba 一个gydF4y2Ba BgydF4y2Ba CDEgydF4y2Ba 接下来的两个最小概率是A和B,所以我们创建了子树:gydF4y2Ba
并更新列表以包含概率为的子树ABgydF4y2Ba
象征gydF4y2Ba 概率gydF4y2Ba ABgydF4y2Ba CDEgydF4y2Ba 现在,我们只剩下两个元素,所以我们构建子树:gydF4y2Ba
ABCDE的概率为gydF4y2Ba ,这是预期的,因为其中一个符号将出现。gydF4y2Ba
下面是我们从树中得到的编码:gydF4y2Ba
象征gydF4y2Ba 编码gydF4y2Ba 一个gydF4y2Ba 11gydF4y2Ba BgydF4y2Ba 10gydF4y2Ba CgydF4y2Ba 01gydF4y2Ba DgydF4y2Ba 001gydF4y2Ba EgydF4y2Ba 000gydF4y2Ba




霍夫曼编码算法gydF4y2Ba
取一列符号及其概率。gydF4y2Ba
选择两个概率最低的符号(如果多个符号具有相同的概率,则任意选择两个)。gydF4y2Ba
用这两个符号创建一个二叉树,标记一个分支为“1”,另一个为“0”。只要在整个问题中标记1或0是一致的,就无所谓了(例如,左边应该总是1,右边应该总是0,或者左边应该总是0,右边应该总是1)。gydF4y2Ba
将两个符号的概率相加,得到新子树的概率。gydF4y2Ba
从列表中删除符号,并将子树添加到列表中。gydF4y2Ba
回到列表中,取两个概率最小的符号/子树,并将它们组合成一个新的子树。从列表中删除原始的符号/子树,并将新的子树添加到列表中。gydF4y2Ba
重复,直到所有的元素被组合。gydF4y2Ba


霍夫曼编码对于单个字符的编码是最优的,但是对于用一种编码方式编码多个字符,其他的压缩方法更好。此外,当每个输入符号是一个已知的独立同分布随机变量,且具有gydF4y2Ba概率gydF4y2Ba这是2的幂的倒数。gydF4y2Ba[1]gydF4y2Ba
另请参阅gydF4y2Ba
参考文献gydF4y2Ba
- ,。gydF4y2Ba霍夫曼编码gydF4y2Ba.检索于2016年7月20日gydF4y2Bahttps://en.wikipedia.org/wiki/Huffman_codinggydF4y2Ba