
跳跃表gydF4y2Ba
跳跃列表是agydF4y2Ba概率数据结构gydF4y2Ba这是建立在gydF4y2Ba链表gydF4y2Ba.跳跃表利用概率在原始链表上构建后续的链表层。每个额外的链接层包含更少的元素,但没有新元素。gydF4y2Ba
你可以把跳跃表想象成地铁系统。每一站都有一列火车停。不过,也有特快列车。这趟列车不会停靠任何独特的站点,但会停靠更少的站点。如果你知道它停在哪里,这就使特快列车成为一个有吸引力的选择。gydF4y2Ba
当您需要并发访问数据结构时,跳过列表非常有用。想象一个gydF4y2Ba红黑树gydF4y2Ba的实现gydF4y2Ba二叉搜索树gydF4y2Ba.如果您在红黑树中插入一个新节点,您可能需要重新平衡整个东西,在此过程中您将无法访问数据。在跳过列表中,如果必须插入一个新节点,那么只有相邻的节点会受到影响,因此在此期间您仍然可以访问大部分数据。gydF4y2Ba
内容gydF4y2Ba
属性gydF4y2Ba
跳跃列表从一个基本的、有序的链表开始。这个列表是排序的,但是我们不能对它进行二分查找因为它是一个链表,我们不能在它里面建立索引。不过,这个订单以后会派上用场的。gydF4y2Ba
然后,在底部列表的顶部添加另一个层。这个新层将有可能包含前一层中的任何给定元素gydF4y2Ba 这种可能性可能有所不同,但通常都是这样gydF4y2Ba 使用。此外,链表中的第一个节点通常被保留,作为新层的头。看看下面的图表,看看一些元素是如何被保留而另一些元素被丢弃的。在这里,刚好有一半的元素被保留在每个新层中,但也可能多或少——这都是概率。在所有情况下,每个新层仍然是有序的。gydF4y2Ba
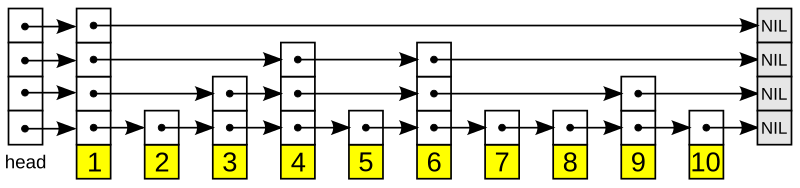 跳过列表的示例实现gydF4y2Ba[1]gydF4y2Ba
跳过列表的示例实现gydF4y2Ba[1]gydF4y2Ba
跳跃列表gydF4y2Ba 具有在其分析中引用的一些重要属性。它的高度是gydF4y2Ba 也就是链表的个数。它有许多不同的元素,gydF4y2Ba 它有一个概率gydF4y2Ba 这通常是gydF4y2Ba
最高的元素(出现在最多列表中的元素)将出现在gydF4y2Ba 平均来说,我们会证明这个gydF4y2Ba晚些时候gydF4y2Ba.如果我们用gydF4y2Ba ,有gydF4y2Ba 列表。这是的平均值gydF4y2Ba .“链表中的每个元素都在它下面的链表中”的另一种说法是“level中的每个元素gydF4y2Ba 存在于水平gydF4y2Ba "gydF4y2Ba
跳跃列表中的每个元素都有四个指针。它指向其左、右、上、下的节点。这些gydF4y2Baquad-nodesgydF4y2Ba将允许我们有效地搜索跳过列表。gydF4y2Ba
时空复杂性gydF4y2Ba
时间gydF4y2Ba
跳跃表的复杂性由于其概率性质而变得复杂。我们将证明它的时间复杂度gydF4y2Ba下面gydF4y2Ba,但现在我们只看结果。但是要注意的是,这些边界是gydF4y2Ba预期gydF4y2Ba或gydF4y2Ba平均情况gydF4y2Ba范围之内。这是因为我们在这个数据结构中使用了随机化:gydF4y2Ba
的gydF4y2Ba最坏的gydF4y2Ba下面是跳跃列表的边界,但我们不担心这些用于分析:gydF4y2Ba
空间gydF4y2Ba
空间比较容易推理。假设跳跃表中的位置总数等于gydF4y2Ba
它等于gydF4y2Ba
因为无穷求和。因此,我们期望的空间利用率很简单gydF4y2Ba
这也是不具体的。很可能,我们的跳跃表可以增长得更高。然而,这是预期的空间复杂度。gydF4y2Ba
算法伪代码gydF4y2Ba
跳跃列表中有四个主要操作。gydF4y2Ba
搜索gydF4y2Ba
这个函数的输入是一个搜索键,gydF4y2Ba关键gydF4y2Ba.这个函数的输出是一个位置,gydF4y2BapgydF4y2Ba,使得这个位置的值是小于或等于的最大值gydF4y2Ba关键gydF4y2Ba.gydF4y2Ba
1 2 3 4 5 6 7gydF4y2Ba |
|
本质上,我们是向下扫描跳过列表,然后向前扫描。gydF4y2Ba
索引gydF4y2Ba
这个功能和gydF4y2Ba搜索gydF4y2Ba,因此我们将省略该代码。gydF4y2Ba
插入gydF4y2Ba
插入的输入是agydF4y2Ba关键gydF4y2Ba.输出是最上面的位置,gydF4y2BapgydF4y2Ba,在该处插入输入。注意,我们正在使用gydF4y2Ba搜索gydF4y2Ba上面的方法。我们使用一个函数叫做gydF4y2BaCoinFlip ()gydF4y2Ba它模仿均匀硬币并返回正面或反面。最后,函数gydF4y2BainsertAfter (a, b)gydF4y2Ba简单地插入节点gydF4y2Ba一个gydF4y2Ba在节点之后gydF4y2BabgydF4y2Ba.gydF4y2Ba
12 3 4 5 6 7 8 9 10 11 12 13 14 15 16gydF4y2Ba |
|
首先,我们总是插入gydF4y2Ba关键gydF4y2Ba放入底部列表的正确位置。然后,我们必须这么做gydF4y2Ba促进gydF4y2Ba新元素。我们通过抛一个公平的硬币来做到这一点。如果是正面,我们就推广新元素。通过抛这个公平的硬币,我们基本上决定了新元素的塔的大小。我们从我们的位置向后扫描,直到我们可以上升,然后我们上升一级,插入我们的gydF4y2Ba关键gydF4y2Ba就在我们现在的位置后面。gydF4y2Ba
当我们抛硬币时,如果正面的数量开始增长大于当前的高度,我们必须确保在跳跃列表中创建新的级别来适应这一点。这个函数的第7-9行为我们处理这个问题。gydF4y2Ba
删除gydF4y2Ba
删除利用了gydF4y2Ba搜索gydF4y2Ba操作上又比上简单gydF4y2Ba插入gydF4y2Ba操作。我们将通过更详细地编写伪代码来节省空间。gydF4y2Ba
1 2 3 4 5 6gydF4y2Ba |
|
删除可以通过多种方式实现。自从我们找到第一个gydF4y2Ba关键gydF4y2Ba,它将连接到的所有其他实例gydF4y2Ba关键gydF4y2Ba,我们可以很容易地一次性删除它们。gydF4y2Ba
跳过列表的高度gydF4y2Ba
之前我们说过会有gydF4y2Ba 列表总数。但是为什么呢?如果每个新创建的关卡都是基于概率去完成,我们又如何能够知道这一点呢?gydF4y2Ba
的概率gydF4y2Ba 这是跳跃表中的一个元素gydF4y2Ba 与gydF4y2Ba 总元素达到了这个级别gydF4y2Ba 只是gydF4y2Ba
因为如果概率是gydF4y2Ba 然后为了创造一个新关卡,我们将为每个元素投硬币,看看它是否应该被包含进去。所以,在的概率gydF4y2Ba至少有一个gydF4y2Ba的gydF4y2Ba 元素到达关卡gydF4y2Ba 是gydF4y2Ba
让我们用一些数字来看看这意味着什么。如果gydF4y2Ba 然后gydF4y2Ba
如果gydF4y2Ba 稍微增加到gydF4y2Ba ,然后gydF4y2Ba
这意味着,如果gydF4y2Ba ,有gydF4y2Ba百万分之一gydF4y2Ba任何一个特定元素进入顶层的几率。当然,这种分析并不严格,但具有高概率(这个词在随机化算法中经常使用),gydF4y2Ba 的高度gydF4y2Ba .gydF4y2Ba
证明的复杂性gydF4y2Ba
正如我们前面所讨论的,跳跃表的最坏情况非常糟糕。事实上,跳过列表的高度可以延伸到gydF4y2Ba
因为我们用的是随机抛硬币。然而,这种分析是不公平的,因为跳跃表的平均性能要好得多。我们来看看这个操作gydF4y2Ba搜索gydF4y2Ba.这是跳过列表的主要关注点,因为两者都有gydF4y2Ba插入gydF4y2Ba而且gydF4y2Ba删除gydF4y2Ba都是用同样的方法证明的。gydF4y2Ba
搜索gydF4y2Ba
有两个嵌套gydF4y2Ba而gydF4y2Ba在这个函数中循环。外部循环类似于“向下扫描”跳转列表,内部循环类似于“向前扫描”跳转列表。gydF4y2Ba
我们已经证明了gydF4y2Ba以上gydF4y2Ba这是高度gydF4y2Ba 的值gydF4y2Ba 所以,跳跃表向下移动的最大次数是gydF4y2Ba
现在,让我们限定前进扫描的次数。假设我们扫描了gydF4y2Ba 水平键gydF4y2Ba 在我们降落到地面之前gydF4y2Ba .我们进入这个级别后扫描的每个后续键都不能存在于这个级别中gydF4y2Ba 否则我们早就看到了。概率是gydF4y2Ba任何gydF4y2Ba给定的键在这个级别是在级别gydF4y2Ba 是gydF4y2Ba 这意味着一旦我们下降,我们在新关卡中遇到的键的预期数量是2 agydF4y2Ba 操作。gydF4y2Ba
我们的两步,向下扫描和向前扫描gydF4y2Ba 而且gydF4y2Ba 时间,分别。这意味着我们搜索的总时间是gydF4y2Ba
如果这个分析感觉类似于gydF4y2Ba二叉搜索树gydF4y2Ba,那是因为它就是!如果仔细观察跳跃列表,它就像一棵树,较低的级别比较高的级别大。gydF4y2Ba
参考文献gydF4y2Ba
- 穆勒,W。gydF4y2Ba维基百科跳过列表gydF4y2Ba.检索于2016年4月20日gydF4y2Bahttps://en.wikipedia.org/wiki/Skip_listgydF4y2Ba