
匈牙利最大匹配算法
的匈牙利匹配算法,也称为Kuhn-Munkres算法,是一种 算法,可以用来寻找最大重量的匹配在一式两份的图,有时被称为分配问题.二部图可以很容易地用邻接矩阵,其中边的权值是项。用邻接矩阵来考虑图对匈牙利算法是有用的。
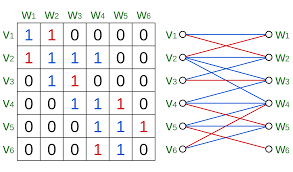 匹配对应于邻接矩阵中1的选择,每行每列最多一个1。
匹配对应于邻接矩阵中1的选择,每行每列最多一个1。
匈牙利算法解决了以下问题:
在完全二部图中 ,找到最大权值匹配。(回想一下,最大权值匹配也是完美匹配。)
这也可以用来找到最小权重匹配。
假设你正在举办一个派对,你想要一个音乐家表演,一个厨师准备食物,还有一个清洁服务来帮助清理派对后的环境。有三家公司分别提供这三种服务,但一家公司一次只能提供一种服务(即B公司不能同时提供清洁工和厨师)。你正在决定你应该从哪家公司购买每项服务,以最大限度地减少聚会的成本。你意识到这是赋值问题的一个例子,并开始用下面的信息做一个图:
公司 音乐人成本 厨师成本 清洁费用 公司 108美元 125美元 150美元 B公司 150美元 135美元 175美元 公司C 122美元 148美元 250美元 你能把这个表建模成图表吗?节点是什么?边是什么?
节点是公司和服务。这些优势是由价格决定的。

解决上述问题的一些方法是什么?因为上面的表格可以被认为是 矩阵,人们当然可以用蛮力来解决这个问题,检查每个组合,看看哪个能产生最低的价格。然而,有 组合检查,并为大 ,这种方法很快就会变得非常低效。
利用邻接矩阵的匈牙利算法
考虑到上面例子中的成本矩阵,匈牙利算法在这个关键思想上进行操作:如果成本矩阵的任何一行或列的所有条目都加上或减去一个数字,那么结果成本矩阵的最优分配也是原始成本矩阵的最优分配。
匈牙利方法[1]
用每一行中最小的条目减去该行中所有其他条目。这样行中最小的元素就等于0。
用每列中最小的条目减去该列中所有其他条目。这将使列中最小的元素现在等于0。
通过具有0项的行和列绘制直线,以便尽可能少地绘制直线。
如果有 画好线后,零的最佳分配是可能的,算法也就完成了。如果行数小于 ,则还没有达到最优的零数。执行下一步。
找到没有被任何行覆盖的最小的项。从未划掉的每一行中减去这一项,然后把它加到划掉的每一列中是划掉了。然后,执行步骤3。
用上面描述的匈牙利算法求解介绍中的例子的最优解。
这是初始邻接矩阵:
用每行中最小的值减去该行中其他值:
现在,用每一列中最小的值减去该列中所有其他值:
通过具有0项的行和列绘制直线,以便绘制尽可能少的直线:
画了2条线,2小于3,所以还没有最佳的0个数。
找到没有被任何行覆盖的最小的项。从未划掉的每一行中减去这一项,然后将其添加到被划掉的每一列中。然后,执行步骤3。
2是最小的项。
首先,从未覆盖的行中减去:
现在添加到覆盖列:
现在回到步骤3,在有0项的行和列中画线:
有3行(这是 ),这样就完成了。赋值将是矩阵中0所在的位置,这样每一行和每列只有一个0是赋值的一部分。
替换原来的值:
匈牙利算法告诉我们,与C公司的音乐家、B公司的厨师和A公司的清洁工一起去最便宜。
我们可以用蛮力来验证这一点。
- 108 + 135 + 250 = 493
- 108 + 148 + 175 = 431
- 150 + 125 + 250 = 525
- 150 + 148 + 150 = 448
- 122 + 125 + 175 = 422
- 122 + 135 + 150 = 407。
我们可以看到407是最低的价格,与匈牙利算法确定的分配相匹配。









利用图的匈牙利算法
匈牙利算法也可以通过操纵二部图的权重来执行,以找到稳定的最大(或最小)权重匹配。这可以通过找到一个可行的标签一个完全匹配的图,其中一个完全匹配表示为每个顶点只有一条匹配边。
我们怎么知道这会产生一个最大权值匹配?
完全匹配上的可行标记返回最大加权匹配。
假设每条边 在图表中 连接两个顶点和每个顶点 只覆盖一次。由此,我们得到如下不等式: 在哪里 有完全匹配的吗 由随机分配的顶点创建,并且 是否是节点的数字标签 .
这意味着 是任何完全匹配代价的上界。
现在我们 完美匹配 ,然后
所以 而且 是最优的。
通过为每个单独的节点分配任何权重来开始算法,以形成图的可行标记 .这种标记将通过为分配寻找扩展路径来改进,直到找到最优路径。
一个可行的标签标签是这样的吗
,在那里 是二部图一侧的节点集合, 是另一组节点, 标签是 等等,以及 边的权值在中间吗 而且 .
一种简单可行的标记方法是用一条边到节点的最大权值来标记一个节点。这肯定是一个可行的标记,因为如果 节点是否已连接 ,标签 加上标签 大于或等于权值 对所有 而且 .
 节点的可行标记,其中标记为红色[2].
节点的可行标记,其中标记为红色[2].
想象一下,有四个足球运动员,每个人都能在球场上踢几个位置。团队经理已经量化了他们在每个位置上的技能水平,以使任务更容易。
 如何分配玩家位置以最大化他们提供的技能点数?
如何分配玩家位置以最大化他们提供的技能点数?
该算法首先用最大权值标记图一侧的所有节点。这可以通过找到最大加权边并用它标记相邻节点来实现。此外,将图形与这些边匹配。如果一个节点有两条最大边,不要连接它们。
 虽然伊娃最适合打防守,但她不能同时打防守和中路!
虽然伊娃最适合打防守,但她不能同时打防守和中路!
如果匹配是完美的,算法就会因为存在最大权值的完美匹配而完成。否则,将存在两个未连接到任何其他节点的节点,如Tom和Defense。如果是这种情况,开始迭代。
通过寻找没有匹配的非零标签顶点来改进标记,并尝试为它找到最佳赋值。形式上,匈牙利语匹配算法可以按照如下定义执行:
匈牙利图算法[3]
鉴于:标签 ,一个相等图 ,初始匹配 在 ,和一个未匹配顶点 而且
增加匹配
路径是增加为 在 如果它在匹配的边和不匹配的边之间交替,并且第一个顶点和最后一个顶点是免费的顶点,或无与伦比,在 .我们将从顶点开始跟踪一个候选扩展路径 .
如果算法找到一个不匹配的顶点 ,添加到现有的扩展路径上 通过添加 来 段。
通过替换边缘来翻转匹配 在扩展路径中没有的边 换句话说,这些边
改进标签
而且 在哪里 而且 表示候选扩展交替路径之间的匹配和不匹配的边。
让 是in中每个节点的邻居 沿着边缘 这样 .
如果 ,那么我们不能增加交替路径的大小(因此不能进一步增大),所以我们需要改进标记。
让 是最小的 在所有的 而且 .
改进标签 来 :
- 如果 然后
- 如果 然后
- 如果 而且 然后
标签是否有效
把它们放在一起:匈牙利算法
从匹配开始 ,有效的标签 ,在那里 被定义为标签 .
这些步骤直到找到完美的匹配 当 是完美的
- (a)寻找一个扩大的路径
- (b)如果不存在增广路径,则改进标记,然后返回步骤(a)。
每一步都会增加匹配的大小 或者它会增加标记边的大小, .这意味着该过程将最终终止,因为图中只有这么多边 .[4]
当进程结束时, 将是一个完美的匹配。由Kuhn-Munkres定理,这意味着匹配是一个最大权值匹配。
上面定义的算法可以在足球场景中实现。首先,识别出冲突的节点,这意味着存在一个必须重新配置的交替树。
 防守,伊娃,中路和汤姆之间有交替路径。
防守,伊娃,中路和汤姆之间有交替路径。
要找到最合适的节点,就要找到最小值 ,如上面步骤4中定义的,其中 标签是播放器吗 标签是位置吗 而且 就是那条边的权重。
的 计算每个不匹配节点的最小值,其中最小值为2,在Tom打中间
然后对标签进行增强,并在示例中绘制出新的边。注意防守和中路下降了2点,而伊娃的技能集恢复了2点。然而,这是意料之中的,因为伊娃不能同时打两个位置。
 增加路径会导致节点重新标记,从而产生最大加权路径。
增加路径会导致节点重新标记,从而产生最大加权路径。
这些新的边完成了图的完美匹配,这意味着已经找到了一个最大加权图,算法可以终止。
复杂性
本文将参照基于图的技术分析算法的复杂性,但结果与基于矩阵的算法相同。
算法分析[3]
在每一个 或 第一步,算法在匹配中添加一条边,这就发生了 次了。
这需要 是时候找到用于增强的正确顶点了(如果有的话),它是正确的 是时候翻转匹配了。
改进标签 时间来寻找 并相应地更新标签。我们可能要改进标签,直到 乘以,如果没有增广路径。这总共是 时间。
总之,有 每次迭代 工作,导致总运行时间为 .
另请参阅
参考文献
- Bruff D。分配问题与匈牙利方法.检索2016年6月26日,从http://www.math.harvard.edu/archive/20_spring_05/handouts/assignment_overheads.pdf
- Golin, M。二部匹配&匈牙利方法.检索检索2016年6月26日,从http://www.cse.ust.hk/~golin/COMP572/Notes/Matching.pdf
- Grinman,。加权二部图的匈牙利算法.检索2016年6月26日,从http://math.mit.edu/~rpeng/18434/hungarianAlgorithm.pdf
- Golin, M。二部匹配&匈牙利方法.检索2016年6月26日,从http://www.cse.ust.hk/~golin/COMP572/Notes/Matching.pdf