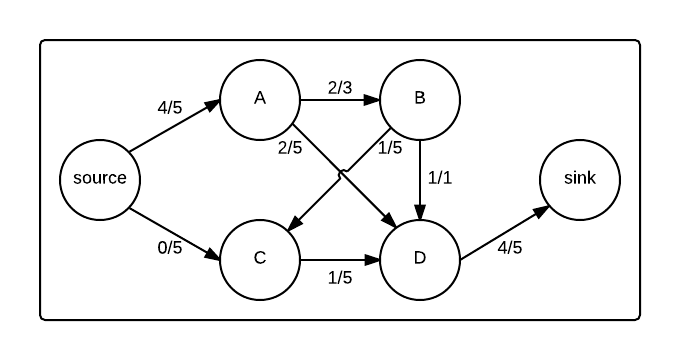
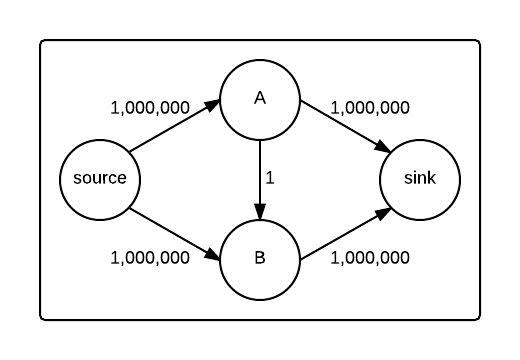
埃德蒙斯-卡普根据许多证据<一个href="//www.parkandroid.com/wiki/big-o-notation/" class="wiki_link" title="复杂性" target="_blank">复杂性都被描述为<一个href="//www.parkandroid.com/wiki/ford-fulkerson-algorithm/" class="wiki_link" title="Ford-Fulkerson" target="_blank">Ford-Fulkerson.来证明这个实现运行在<年代pan class="katex">
O(V⋅E2),必须证明两种说法是正确的。首先,在算法的每次迭代中,源与残差图中所有其他顶点之间的最短路径必须增加<一个href="//www.parkandroid.com/wiki/monotonically/?wiki_title=monotonic" class="wiki_link new" title="单调" target="_blank" rel="nofollow">单调.也就是说,它是总是增加。第二个是心流扩展的总数<年代pan class="katex">
O(V⋅E).残差图中的最短路径总是递增(因而在原图中递减),且残差图中最短路径最多<年代pan class="katex">
V⋅E流的增加,那么复杂性的界限就会得到很好的定义。
单调递增路径长度
为了证明残差图中所有顶点的最短路径都是递增的,可以考虑一个矛盾。因此,考虑流量增加导致最短路径减少。想象一下,<年代pan class="katex">
f流之前是这样的强化吗<年代pan class="katex">
fˊ是之后的流动。有一个顶点,<年代pan class="katex">
v,这样<年代pan class="katex">
d我年代t一个ncefˊ(年代,v)<d我年代t一个ncef(年代,v)因为我们的矛盾流小于原始流。定义一个顶点,<年代pan class="katex">
u,这样就有了一条路径<年代pan class="katex">
年代来<年代pan class="katex">
v通过<年代pan class="katex">
u这是最短路径<年代pan class="katex">
年代来<年代pan class="katex">
v在<年代pan class="katex">
Gf.也就是说最短路径<年代pan class="katex">
年代来<年代pan class="katex">
v1比最短路径大吗<年代pan class="katex">
年代来<年代pan class="katex">
u为简单起见,所以
d我年代t一个ncefˊ(年代,u)=d我年代t一个ncefˊ(年代,v)−1.
最短路径<年代pan class="katex">
年代来<年代pan class="katex">
u没有随着新的流量而减少吗<年代pan class="katex">
fˊ因为我们的选择<年代pan class="katex">
v,所以
d我年代t一个ncefˊ(年代,u)≥d我年代t一个ncef(年代,u).
然而,边缘<年代pan class="katex">
(u,v)不能在残差图中,<年代pan class="katex">
Gf.如果是,就会有以下关系(注意我们使用的是整型边长):
d我年代t一个ncef(年代,v)d我年代t一个ncef(年代,v)d我年代t一个ncef(年代,v)≤d我年代t一个ncef(年代,u)+1≤d我年代t一个ncefˊ(年代,u)+1≤d我年代t一个ncefˊ(年代,v).(通过三角形不等式)(因为最短路径减小fˊ)(因为(s, u)和(s, v)之间的关系)
最后一个等式违背了这种关系
d我年代t一个ncefˊ(年代,v)<d我年代t一个ncef(年代,v).
换句话说,最短路径实际上并没有随着流量而减少<年代pan class="katex">
fˊ.这个矛盾证明告诉我们最短路径在残差图上单调增长,它限定了Edmonds-Karp的一次迭代的长度为<年代pan class="katex">
O(E).
的迭代次数
下一个证明涉及到Edmonds-Karp为了找到网络的最大流量而必须进行的迭代次数。我们的目标是证明有<年代pan class="katex">
O(V⋅E)Edmonds-Karp迭代。
边定义为<年代trong>至关重要的在一条增广路径上,当且仅当边的剩余容量等于路径的剩余容量。换句话说,临界边的容量将被这条扩展路径所填满。一旦我们增广了这条路径,这条有问题的边就会从残差网络中消失。我们必须证明每一个<年代pan class="katex">
∣E∣边缘最多是临界的<年代pan class="katex">
2∣V∣次了。
让<年代pan class="katex">
u和<年代pan class="katex">
v为图中由一条边连接的顶点,并设<年代pan class="katex">
年代是源。当这条边是关键的时候,距离关系就会
d我年代t一个ncef(年代,v)=d我年代t一个ncef(年代,u)+1.
一旦这个流动扩大,正如我们已经看到的,边缘<年代pan class="katex">
(u,v)将从残差网络中消失。这条边不会再出现,除非水流从<年代pan class="katex">
u来<年代pan class="katex">
v是减小的,这只发生在边<年代pan class="katex">
(v,u)出现在扩展路径上。如果<年代pan class="katex">
fˊ当这种情况发生时,心流是什么
d我年代t一个ncefˊ(年代,u)=d我年代t一个ncefˊ(年代,v)+1.
回顾本节的第一个证明<年代pan class="katex">
d我年代t一个ncef(年代,v)≤d我年代t一个ncefˊ(年代,v),我们有
d我年代t一个ncefˊ(年代,u)d我年代t一个ncefˊ(年代,u)d我年代t一个ncefˊ(年代,u)=d我年代t一个ncefˊ(年代,v)+1≥d我年代t一个ncef(年代,v)+1≥d我年代t一个ncef(年代,u)+2.
最后一个方程非常重要。据说在这段时间里<年代pan class="katex">
(u,v)第一次成为关键<年代pan class="katex">
(当流<年代pan class="katex">
f),到下一个关键时刻<年代pan class="katex">
(当流<年代pan class="katex">
fˊ),光源与<年代pan class="katex">
u增加了至少2.
最短路径上的中间顶点<年代pan class="katex">
年代来<年代pan class="katex">
u不能包含<年代pan class="katex">
年代,<年代pan class="katex">
u,或<年代pan class="katex">
t,也就是到顶点的距离<年代pan class="katex">
u最多是<年代pan class="katex">
∣V∣−2.这个分数的分母是2,因为每次有一条边变得临界时,到源的距离至少增加2。所以,<年代pan class="katex">
(u,v)可以成为最关键的吗<年代pan class="katex">
2∣V∣−2次数,总共为<年代pan class="katex">
O(∣V∣)次了。
因为有<年代pan class="katex">
O(∣E∣)这条边的顶点对总数<年代pan class="katex">
(u,v),成为关键<年代pan class="katex">
O(∣V∣)乘以,Edmonds-Karp可以经历的迭代总数是<年代pan class="katex">
O(∣V∣⋅∣E∣).