
无监督学习
阿卡什Padmanabha做出了贡献
使用
无监督学习在很多情况下都有使用,下面将详细介绍其中的一些情况。
聚类-聚类是一种流行的无监督学习方法,用于将相似的数据分组在一起(聚类)。k - means聚类是聚类数据的一种流行方法。如上例所示,由于数据没有标记,因此群集不能与数据的“正确”群集进行比较。
异常检测-异常检测,或称为异常值检测,是对不符合数据集其余部分的数据的标识。这个任务不需要标记数据,只要数据集中的大部分数据点是“正常的”,算法寻找与其余数据最不相似的数据点。
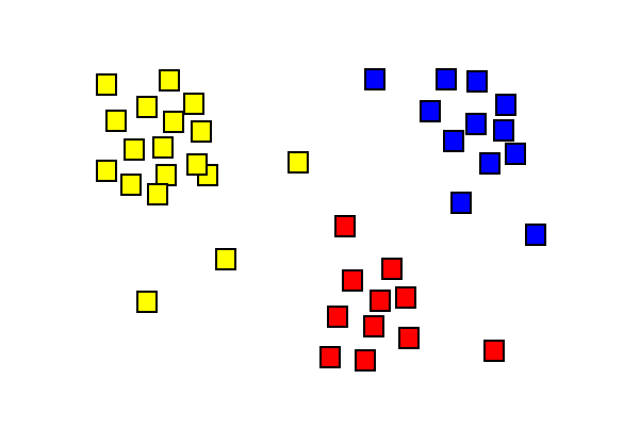
离群值的例子[2]
在本例中,我们看到两个数据集群(G1和G2),以及异常值O1和O2。异常检测是一种无监督学习,即使数据没有标记,也可以确定O1和O2是异常值。的一种方法是再邻居,一个数据点被标记为离群值或非离群值k最近的邻居和数据点与这些邻居之间的距离。
神经网络
潜在的变量
一个统计无监督学习的方法是矩量法的一种估计方法参数的概率分布.该算法使用时刻的未知参数,也就是预期值对参数的幂,确定参数的分布。
特别地,用矩量法来学习的参数潜变量模型。这些统计模型包含未观察到的变量。潜在变量模型的一个例子是基于文档的单词(观察变量)确定主题(潜在变量)的机器学习任务。例如,带有“狗”、“骨头”和“咀嚼”的文档与“狗”的主题有关,带有“猫”、“挠”和“喵”的文档与“猫”的主题有关,等等。在这种任务中,矩量法(一种无监督学习过程)在提取文档主题时非常有用。
此外,采用(EM)算法是用无监督学习找到潜在变量的另一种方法。该算法使用估计参数的期望,以及最大化该期望,以确定潜在变量,并在其详细的wiki中进一步描述。总的来说,矩量法和矩量法是无监督学习在机器学习任务中的重要应用。
参考文献
- hellisp。集群- 2. - gif.检索自2016年6月1日https://en.wikipedia.org/wiki/File:Cluster-2.svg
- Osrecki。二维离群值Example.png.检索自2016年6月1日https://commons.wikimedia.org/wiki/File:Two-dimensional_Outliers_Example.png
{kind=link}
{kind=link}
引用:无监督学习。Brilliant.org.检索从//www.parkandroid.com/wiki/unsupervised-learning/