
展开的列表
特性
 展开的列表
展开的列表
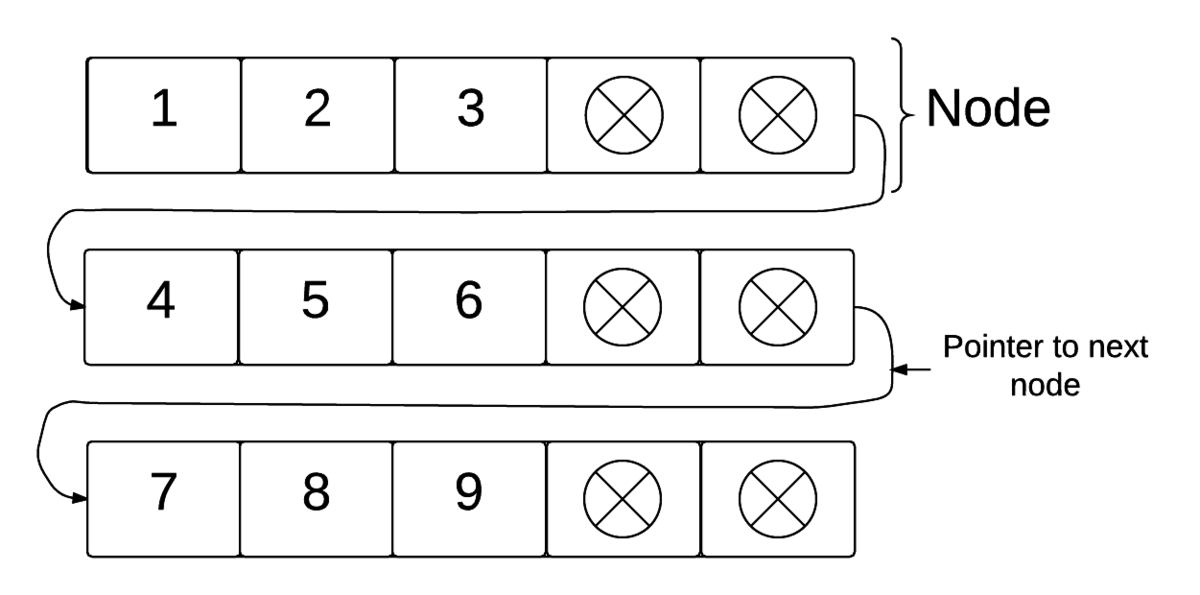
展开的链接列表基本上是一个链接列表,其中节点包含值数组而不是单个值。每个节点处的阵列可以保存典型的阵列可以诸如原始类型和其他阵列的任何东西抽象数据类型。每个节点都有最大数量的值,它可以保持,典型的实现将每个节点保持在平均值左右 容量。当某些数组变得过于满满时,它通过阵列之间的值移动这一点。
展开链接列表的开销是每个节点的比特 - 现在每个节点都必须存储其数组可以保持的最大值数。但是,在按值分析时,它远低于常规链接列表。随着每个节点中的数组的最大大小增加,每个值下降所需的平均存储空间。当值的类型非常小(例如,比特),空间优势甚至更大。
在本质上,展开链表结合阵列和链表。它采用阵列的存储的超快速索引和地方的优势。这两种利益从静态数组的基本特性干。此外,同时也保留了链表报价节点的插入和删除的优势。
插入和删除
您在展开的链接列表中插入和删除元素的算法可能因实现而异。通常,低水位标记处于50% - 意味着如果在无法符合元素的节点中发生插入,则会创建一个新节点,并且将原始节点的一半插入其中。相反,如果我们删除元素和该节点下降到50%的节点中的值数,我们将从相邻阵列中移动元素,以填充超过50%以上。如果该阵列还降低50%,则我们合并两个节点。
通常,这将平均节点放在约70-75%的利用率范围内。与之相比链接名单,开销与合理的节点大小相当小。链接列表每节点需要大约2或3件开销。展开的链接列表在其元素中摊销了这个开销,给它 这接近的开销大批。
您可以更改低水位标记以更改展开链接列表的性能。通过增加它,您将增加每个节点的平均利用率。但是,这将以更频繁的分裂和合并来实现。
算法伪代码
用于插入和删除的算法如下所示。在这个例子中,每个节点具有阵列数据,当前当前在该数组中的多个元素包含numElements,以及指向下一个节点的指针下一个。
1 2 3 4 5 6 7 8 9 10 11 |
|
1 2 3 4 5 6 7 8 9 10 11 |
|
对于这两个功能,程序员可以采用许多自由。例如,在插入在哪个节点决定尝试插入是由程序员。它可以是第一个节点,它可以是最后一个节点,也可以在一些排序或分组要维护为前提。通常,这将是具体的那种,你将与工作数据的。
时间和空间复杂性
展开的链接列表难以分析,因为它们以这么多不同的方式实现,并且根据数据使用一些不同的变化。然而,由于跨元素的摊销,它们具有良好的时光和空间分析。
时间
要插入元素,必须先查找要插入的节点。这是 。如果该节点是不是满的,你做。如果是满的,你必须创建一个新的节点,并在移动值。这个过程不依赖于在链表总价值,所以它是恒定的时间。删除的工作方式相同,在相反的方式。我们充分利用这些固定时间的操作,由于这样的事实,链表可以彼此之间更新他们的三分球比较快,独立的链表的大小。
索引是展开的链接列表的另一重要品质。然而,它是高度依赖于缓存,我们将覆盖以下。
| 手术 | 复杂 |
| 插入 | |
| 删除 | |
| 索引 | |
| 搜索 |
对于展开的链接列表,重要的是要记住,真正的益处是以实际应用的形式出现,不一定是渐近分析。
空间
展开链接列表所需的空间因而异 到 在哪里 是每个节点的开销, 是每个节点的最大元素,以及 是节点的数量。虽然这一点,在最后等于与其他线性数据结构相同的渐近空间链接名单,它知道它是更好,因为它遍及许多元素的开销是非常重要的。
| 复杂 | |
| 空间 |
缓存
展开的链接列表的真正福利以缓存的形式出现。展开的链接列表在索引时利用了这一点。
当一个程序访问某些数据形成的内存,它拉了整个页面。如果程序没有找到正确的值,我们称之为一缓存小姐。这意味着我们可以在指数最多的展开链表 高速缓存未命中。这是最多的因素 比常规链接列表更快。
我们可以通过考虑到缓存行的大小来进一步分析这一点,我们将调用 。通常,每个节点数组的大小, ,将等于或是高速缓存行大小的倍数来优化取过程。在该分析中,每个节点可以在遍历 缓存未命中,所以我们可以遍历列表 。这是非常接近的optimial高速缓存未命中值 。