
监督学习GydF4y2Ba
监督学习GydF4y2Ba是个GydF4y2Ba机器学习GydF4y2Ba确定a的任务GydF4y2Ba功能GydF4y2Ba从标记的数据。例如,在检测到帖子的机器学习算法中,训练集将包括标记为“垃圾邮件”的帖子,标记为“不是垃圾邮件”,以帮助教导算法如何识别差异。监督学习算法推断GydF4y2Ba功能GydF4y2Ba从标数据,并使用新的实例此功能。监督学习是机器学习的核心理念,在诸如区域使用GydF4y2Ba生物信息学GydF4y2Ba那GydF4y2Ba计算机视觉GydF4y2Ba, 和GydF4y2Ba模式识别GydF4y2Ba。GydF4y2Ba
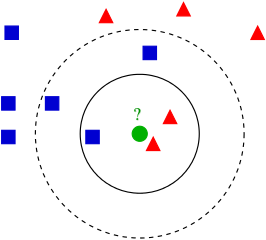 一个例子GydF4y2BaK-最近的邻居GydF4y2Ba,一个监督学习算法。该算法通过观察确定数据点的分类其GydF4y2BaK.GydF4y2Ba最近的邻居。GydF4y2Ba[1]GydF4y2Ba
一个例子GydF4y2BaK-最近的邻居GydF4y2Ba,一个监督学习算法。该算法通过观察确定数据点的分类其GydF4y2BaK.GydF4y2Ba最近的邻居。GydF4y2Ba[1]GydF4y2Ba
内容GydF4y2Ba
概述GydF4y2Ba
监督学习开始通过在工作GydF4y2Ba训练GydF4y2Ba数据集,即标有其相应的输出数据点。例如,上面的图像中,训练集将是蓝色正方形和红色三角形,并且对于每个数据点处的标签的位置将是点是否为蓝色正方形或红色三角形。学习算法寻找函数GydF4y2Ba 可以映射输入数据GydF4y2Ba 他们适当的标签GydF4y2Ba 好。该算法的总体目标是GydF4y2Ba概括GydF4y2Ba此功能使其在未知的示例中表现良好。GydF4y2Ba
最广泛使用的监督学习算法是:GydF4y2Ba
风险GydF4y2Ba
在确定特定监督学习算法有多好,两种类型GydF4y2Ba风险GydF4y2Ba可以最小化:GydF4y2Ba
- 经验风险GydF4y2Ba- 经验风险是GydF4y2Ba预期的GydF4y2Ba损失GydF4y2Ba功能GydF4y2Ba 从训练数据集的监督学习算法推断。例如,如果GydF4y2Ba 正确地映射所有培训数据点GydF4y2Ba 各自的标签GydF4y2Ba ,经验风险为0。在数学上,对于经验风险函数GydF4y2Ba 培训数据点是GydF4y2Ba , 在哪里GydF4y2Ba 被定义的用户GydF4y2Ba损失功能GydF4y2Ba确定的不正确地标记的特定数据点的惩罚。GydF4y2Ba
在最小化经验风险,监督学习算法传授给训练数据尽可能好地匹配。然而,如下面的图像中,溶液可以最小化经验风险而不为未知的数据点的良好候选者的功能。这就是所谓的GydF4y2Ba过度装满GydF4y2Ba当拟议功能更加侧向噪声而不是实际数据时,发生在此时,如下所示,发生在噪声上,如下所示。GydF4y2Ba
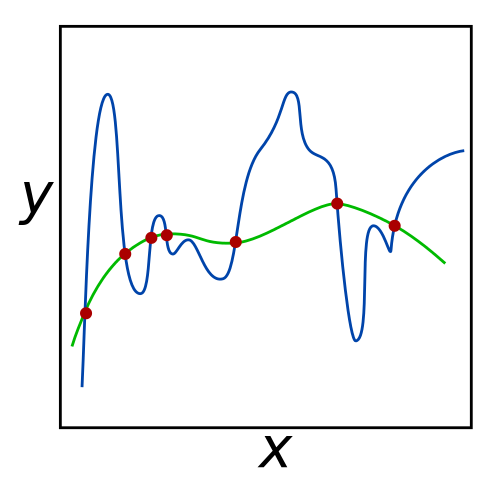 对于给定的红色输入点,绿线和蓝线都尽量减少误差为0。但是,绿线可能会在预测未知数据点的坐标更成功,因为它似乎GydF4y2Ba概括GydF4y2Ba数据好。GydF4y2Ba[2]GydF4y2Ba
对于给定的红色输入点,绿线和蓝线都尽量减少误差为0。但是,绿线可能会在预测未知数据点的坐标更成功,因为它似乎GydF4y2Ba概括GydF4y2Ba数据好。GydF4y2Ba[2]GydF4y2Ba
- 结构风险GydF4y2Ba- 结构风险用于防止监督的学习算法过度拟合训练数据。结构风险最小化引入了一个GydF4y2Ba正则罚款GydF4y2Ba可更喜欢别人一定的解决方案。在数学上,正规化罚函数GydF4y2Ba 与经验风险一起使用以确定解决方案。具体而言,结构风险最小化GydF4y2Ba , 在哪里GydF4y2Ba 是经验的风险和GydF4y2Ba 是一个用户定义的参数,用于控制所述正则化的惩罚。例如,如果GydF4y2Ba ,优化问题最小化经验风险依旧。GydF4y2Ba
确定适当价值的好方法GydF4y2Ba 是使用GydF4y2Ba交叉验证GydF4y2Ba,一种在训练数据上培训监督算法的方法,并在A上测试其性能GydF4y2Ba验证GydF4y2Ba数据集(已知正确标签的数据点)。然后更新该算法以最小化验证集的错误,同时仍在训练在训练数据集上。描述了该行动的示例GydF4y2BaRidge回归GydF4y2Ba,并且广泛用于确定在未知数据上表现良好的功能。GydF4y2Ba
挑战GydF4y2Ba
有构建监督学习算法许多挑战,下面四个重要的那些描述。GydF4y2Ba
- 偏差 - 方差权衡GydF4y2Ba- 假设一个监督学习算法对多个数据集训练。如果该算法无法正确标注具体的数据来看,它被认为是GydF4y2Ba偏GydF4y2Ba对于那个输入。另外,如果算法在不同的数据集上训练时产生不同的输出值,则据说它具有高GydF4y2Ba方差GydF4y2Ba。实证风险集中于偏见,而结构性风险集中于差异。通常有偏差和方差,其中低偏压意味着高方差和反之亦然之间的折衷。一种用于监控运算问题是要找到这两个概念是最适合与未知数据之间的平衡点。GydF4y2Ba
 蓝色曲线最小化的数据点(低偏压)的错误,但具有高的方差。相反,黑线不减少错误(具有较高的偏差),但数据拟合良好(低方差)。GydF4y2Ba[3]GydF4y2Ba
蓝色曲线最小化的数据点(低偏压)的错误,但具有高的方差。相反,黑线不减少错误(具有较高的偏差),但数据拟合良好(低方差)。GydF4y2Ba[3]GydF4y2Ba 复杂GydF4y2Ba- 是,监督学习算法试图模仿功能,可以是简单的或复杂的。如果预期的功能简单,算法应具有低方差以及拟合数据。但是,如果预期功能复杂,算法应具有高方差适应未知的数据点。监督学习算法应适当地根据数据量和功能将被期望的类型能够确定方差。GydF4y2Ba
许多尺寸GydF4y2Ba- 当监督学习算法给出由许多维度组成的数据集时,它可能会尝试识别不相关因子之间的趋势。这增加了GydF4y2Ba方差GydF4y2Ba推断功能,可以降低算法的准确性。解决此问题的两种方式包括运行不同的算法来丢弃不相关的变量并将输入数据缩小到较低数量的维度。GydF4y2Ba
数据格式GydF4y2Ba- 如果训练数据在其标签或在其数据值有错误,监督学习算法不应该试图完全匹配的训练例子。这可以导致GydF4y2Ba过度装满GydF4y2Ba并不会为未知值表现良好。此外,如果训练数据中包含的冗余信息,监督学习算法可由于过度依赖于具体的实施例表现不佳。过滤数据或适当正规化算法可以缓解这两个问题。GydF4y2Ba
参考GydF4y2Ba
- Ajanki,A.GydF4y2Bak近邻classificationnb的实施例GydF4y2Ba。检索2016可以月28日,从GydF4y2Bahttps://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm#/media/File:KnnClassification.svgGydF4y2Ba
- 尼古洛洛,。GydF4y2BaRegularization.svgGydF4y2Ba。从2016年5月31日检索到的GydF4y2Bahttps://en.wikipedia.org/wiki/File:Regularization.svgGydF4y2Ba
- Ghiles,。GydF4y2Baoverfitted_data.svg.GydF4y2Ba。从2016年5月31日检索到的GydF4y2Bahttps://en.wikipedia.org/wiki/file:overfitted_data.png.GydF4y2Ba
{kind=link}
{kind=link}