
字符串

基本的字符串功能
字符串是大多数现代语言中的内置数据类型,并配有许多有用的操作。字符串数据的常见任务要求我们分析和重新组合它们,并在其中找到模式。模式发现In字符串可以很快变得复杂,而更强大的字符串匹配技术被归为正则表达式篇文章。下面,我们将探讨一些可以用字符串执行的基本操作。
特征提取
字符串中的每个字符都有一个很好的地址,称为索引,可以用来检索它。通常的约定是字符串中第一个字符(从左开始)的索引为0,下一个字符的索引为1,依此类推。在许多语言中,字符串也可以从右侧建立索引,使用负数进行计数。最后一个位置(同样从左边开始计数)被赋值为-1,最右边的第二个字符被索引为-2,以此类推,直到到达字符串的开头。显然,字符串的最大索引是其长度减1。类似地,它的最低索引是-长度,也就是第一个元素的索引。
例如,在字符串中
“Merriweather”的米有索引0从左到右-12年从右边。一个例子胜过许多文字,让我们看看如何在Python中进行字符提取。
>年代=“六边形abcdef”>打印年代[4]#打印索引号为4的字符。“e”
子字符串提取
如果知道子字符串的开始和结束索引,则可以使用索引从字符串中提取子字符串。
>年代=“六边形abcdef”>打印年代[1:4]“bcd”需要注意的是,生成的子字符串比上索引早一个索引结束。
特征提取
可以同时使用正索引和负索引方案。
>年代=“六边形abcdef”>打印年代[-1]#打印最后一个字符。“f”>打印年代[2:-1]#从索引2到(但不包括)最后一个索引打印。“cde”同样,重要的是要注意子字符串在范围结束之前的字符上结束(在Python中,对列表/字符串进行切片是[include:exclusive],因此
: 1会包含索引处的字符吗2但不是-1).负索引的便利之处在于,不需要知道字符串的长度就可以从末尾获得字符。
从字符串中提取子字符串后,通常需要将片段重新组合为另一个字符串。大多数编程语言都包含用于连接两个字符串的运算符。
字符串连接
在Python中,我们可以用
+操作符。
>str1=‘好’>str2=“早晨”>str3=“越南!”>打印str1+' '+str2+' '+str3好早....越南!
子字符串
继续使用我们命名为“字符串”的有序字符组的想法,我们将学习更多关于它们的知识,以便能够使用它们做强大的事情,并最终解决现实生活中的计算问题。
字符串的定义很简单,但这并不意味着它们的适用性有限。它们是基本的构建块,可用于构建更复杂的数据类型以解决问题。熟悉字符串操作是很重要的,因为许多应用程序都需要使用字符串并将它们重新塑造为对计算有用的形式。
下面是一些有用的基本字符串函数:
Python字符串的方法
方法获取子字符串之外
[start_inclusive: end_exclusive]表示法中,可以提供第三个参数来添加一个“步长”大小,该大小将定期对开始和结束索引之间的区域进行采样。默认情况下,子字符串方法的开始和结束索引为0而且len (str);因此,如果我们要求[:],我们得到整个字符串。例如:
>str=“abcdefghij”# # # # # # # # 0123456789>str[1:8:2]步长为2的子字符串每2个字符打印一次。#只打印出现在索引1、3、5和7处的字符。“bdfh”>str(::-2]#步长为-2的子字符串每2个字符打印一次,计数从字符串的末尾开始返回。只有出现在索引处的字符# -1, -3 -5, -7, -9将被打印。“jhfdb”很简单!

分裂
因为我们经常收到可变长度的字符串,索引并不总是有用的。数据存储的一种常见形式包括使用通用分隔符分隔项,如逗号、空格、制表符、下划线等。在任何分隔符方案中,用户必须同意不使用分隔字符串作为文件的信息部分,即分隔符只用于划分项的边界,而不是项本身。
由于这是常见的,所以大多数语言中都提供了在这些字符的位置拆分字符串的方法。给定输入字符串和分隔符的标识,则分裂方法将返回组件字符串。
Python字符串split()方法
假设你有一个文件,包含如下形式的字符串,代表各种基因产物:
行= " lacZ_1013aa_betagalactosidase_escherichiacoli "第一个字符串是基因的名称,第二个字符串是其氨基酸残基长度,第三个字符串是酶产物,第四个字符串是起源有机体。
写一个函数这将分解输入字符串并打印酶产物。
首先,我们可以使用
分裂方法来打破行向上到四个字段,这将产生一个字符串数组。然后我们简单地打印第三个元素。
defget_enzyme(ln):分裂=ln.分裂(“_”)enzyme_product=分裂[2]打印enzyme_product因此
>行=lacZ_1013aa_betagalactosidase_escherichiacoli>get_enzyme(行)“betagalactosidase”
翻译
字符串的另一个常见任务是进行字符替换,即替换字符x1, x2,…, xn用另一种字母表y1, y2,…, yn.例如,假设基因组(DNA)中有一个与基因X相对应的区域,其产物是蛋白质X,我们想要找到核糖体用来将信息转化为蛋白质的mRNA。
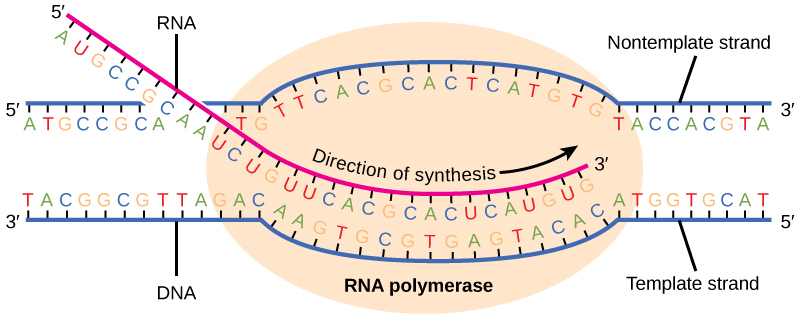
RNA聚合酶读取负链,用鸟嘌呤取代所有胞嘧啶,反之亦然。所有胸腺嘧啶都被腺苷取代。而且,由于碱基尿嘧啶在所有RNA序列中都被用来代替胸腺嘧啶,腺苷就被尿嘧啶取代了。因此我们有
1 2 3 4 |
|
我们如何使用字符串翻译将DNA序列转录成mRNA ?
RNA转录
我们可以使用方法
maketrans从Python字符串模块为这个翻译任务制作一个罗塞塔石碑:
>从字符串进口maketrans>罗塞塔=maketrans(“ATGC”,“UACG”)有了翻译表在手,我们就可以用它将我们的DNA序列转录成RNA。由于核酸序列的5' -> 3'极性,这将与我们的目标mRNA序列相反:
>DNA=“GCGTGAGTACACATGGTGCAT”>rev_mRNA=DNA.翻译(罗塞塔)最后,为了得到mRNA序列,我们将我们的结果反向:
>信使核糖核酸=rev_mRNA(::-1]“AUGCACCAUGUGUACUCACGC”在最后一步中,我们使用子字符串功能来获取整个字符串,并反向运行索引。