
极大极小
在博弈理论,极大极小为最小化最坏情况潜在损失的决策规则;换句话说,玩家会考虑对手对他的策略的所有最佳反应,并在选择策略时让对手的最佳策略提供尽可能大的收益。
minimax的名字来源于迷你当对手选择所给出的策略时,就会考虑到所涉及的损失马克斯最大损失,在分析第一个玩家的决策时很有用,无论是当玩家连续移动还是当玩家同时移动。在后一种情况下,极小极大可以给出纳什均衡如果某些附加条件成立的话。
极大极小也很有用组合游戏在这种情况下,每个头寸都有收益。最简单的例子就是给获胜的位置分配“1”,给失败的位置分配“-1”,但因为除了最简单的游戏,这很难计算,所以中间评估(游戏邦注:特别是针对所讨论的游戏)通常是必要的。在这种情况下,第一个参与者的目标是使位置的评估值最大化,第二个参与者的目标是使位置的评估值最小化,因此应用了极大极小规则。从本质上说,这就是电脑处理游戏的方式国际象棋和Go,尽管极大极小的“朴素”实现可能有各种计算上的改进。
正式的定义
假设球员 选择策略 ,剩下的玩家选择策略配置 .如果 表示玩家的效用函数 在策略配置文件 ,极大极小游戏的定义是
从直觉上讲,最小最大值(对于玩家来说 )是两个等效公式之一:
- 极大极小值是其他玩家可以强迫玩家的最小值 接收,不知道玩家 的策略
- 极大极小值是最大的值 当他被告知其他选手的策略时,他就能保证。
类似地,极大极小被定义为
我们可以直观地理解为:
- maximin是最大价值玩家 当他不知道其他玩家的策略时,他能保证什么
- 最大值是其他玩家可以强制玩家的最小值 接收,同时了解玩家 的策略
例如,考虑以下收益矩阵(行表示第一个玩家的选择,列表示第二个玩家的选择):
| 1 | 2 | 3. | |
| 1 | -1 | -2 | -1 |
| 2 | 2 | 2 | 1 |
| 3. | -1 | -1 | 0 |
双方都可以在三种策略中选择。在这样的回报矩阵中,从第一个玩家的角度来看:
- 的极大极小每一行中最小值的最大值是多少
- 的极大极小每列中最大值的最小值是多少
最大值是- 2,1和-1中最大的(即1)最大值是最小的(即1)最大值是最小的(即1)
这一点非常重要
也就是说,最大值总是大于最大值极小值。
我们可以通过极大极小来直观地理解这一点 有效地选择了他的策略后学习别人的,只会增加他的收益。
在上面的例子中,极大极小和极大极小实际上是相等的。在这种情况下(这种情况并不总是发生!纳什均衡的游戏。
极大极小定理
的极大极小定理建立函数的极小极大值和极大值相等的条件。更准确地说,极大极小定理给出了时间的条件
在形式上,
极大极小定理:
让 是两个紧凑的凸集, 是成对的连续函数 .如果 是凸凹形,即
- 所有的凸都是固定的吗
- 所有的都是凹的吗
然后
极小极大定理在零和博弈中的应用尤其重要,因为它等价于
对于策略有限的零和博弈,存在收益 和一个混合策略对于每个玩家来说
- 参与人1的收益最多 ,即使已知玩家2的策略
- 参与人2可以获得最多的收益 ,即使已知参与人1的策略
这等价于建立纳什均衡.
需要注意的是,极大极小策略可能是混合的;一般来说,
对于每个参与人来说,单纯的极小极大策略并不一定会导致纳什均衡。
例如,考虑收益矩阵
| 1 | 2 | 3. | |
| 1 | 3. | -2 | 2 |
| 2 | -1 | 0 | 4 |
| 3. | -4 | -3 | 1 |
第一个参与人的极大极小选择是策略2,第二个参与人的极大极小选择也是策略2。但两个选择策略2的参与人并不会得到纳什均衡;在知道对方的策略后,任何一方都会选择改变自己的策略。实际上,混合极小极大策略:
- 参与人1以概率选择策略1 概率策略2
- 参与人2以概率选择策略1 概率策略2
是稳定的,并表示纳什均衡。
在组合游戏
在组合博弈中,例如国际象棋去,极大极小算法给出了下一个最优步的选择方法。首先,一个评价函数 从位置集合到实数是必需的,代表第一个玩家的收益。例如,一个国际象棋的评价+1.5的位置明显有利于第一个玩家,而一个评价的位置 是白棋将死的棋局。一旦知道了这个函数,每个玩家就可以将极大极小原则应用到可能的行动树中,从而通过在某个足够深的点截断树来选择自己的下一个行动。
更具体地说,给定一个树使用该函数求叶的可能移动 ,一个球员递归地根据以下方法为每个节点赋值:
- 如果节点的深度是偶数,这意味着第一个玩家在移动,节点的评估是最大孩子们的评价。
- 如果节点的深度是奇数,也就是说第二个玩家在移动,节点的值是最低孩子们的评价。
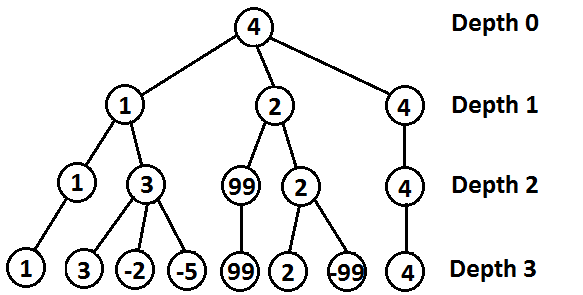
例如,在下面的树中,首先计算叶子的值(99和-99分别代表赢/输的游戏);这将填充树的底部行。在深度2,第一个玩家在移动,所以他应该选择最大化评估的移动。这意味着深度2行的每个求值都是最大它的子树中的数字。在深度1,第二名玩家正在移动,所以他应该选择最小化评估的移动。这意味着深度1行的每个求值都是最低它的子树中的数字。最后,在深度为0时,第一个玩家正在移动,所以他应该选择最大化评价的移动,给出4的总体评价。
当然,像国际象棋和围棋这样的游戏要复杂得多,因为在任何可能的点上都可能有几十种走法(而不是上面例子中的1-3)。因此没完全解决这些游戏使用一个极大极小算法,也就是说,评价函数在一个足够深的树(例如,大多数现代国际象棋引擎应用深度介于16和18)和极大极小用于填写这个相对较小的树。