
分类问题
分类中心话题在哪里机器学习这与教机器如何根据特定的标准将数据分组有关。分类是计算机根据预先确定的特征将数据组合在一起的过程监督式学习.有一个无人管理的版本分类,称为聚类在没有指定类别的情况下,计算机可以根据这些特征对数据进行分组。
分类的一个常见例子是检测垃圾邮件。为了编写过滤垃圾邮件的程序,计算机程序员可以用一组标记为垃圾邮件的类垃圾邮件和标记为非垃圾邮件的普通邮件来训练机器学习算法。我们的想法是制作一个算法,可以从这个训练集中学习垃圾邮件的特征,这样当它遇到新的邮件时,就可以过滤掉垃圾邮件。
分类是当今世界的一个重要工具大数据用于政府、经济、医学等领域的各种决策。研究人员可以访问大量的数据,分类是帮助他们理解数据并找到模式的工具之一。
而机器学习中的分类需要使用(有时)复杂算法分类是人类每天都在做的事情。分类是简单地根据相似的特征和属性将事物分组在一起。当你去杂货店时,你可以相当准确地将食物按食物组分类(谷物、水果、蔬菜、肉类等)。在机器学习中,分类就是教计算机做同样的事情。
直觉
下面是一些分类有用的例子:
分类图片
假设你正在编写一个机器学习程序,它将能够检测肺部的癌症肿瘤。它将肺部x线影像作为输入,并确定是否有肿瘤。如果有肿瘤,我们希望计算机输出“是”,如果没有肿瘤,我们希望计算机输出“否”。我们希望计算机尽可能多地输出正确答案。语音标签假设这个算法的训练集由几张x射线图像组成,其中一半图像包含肿瘤,标记为“是”,另一半图像不包含肿瘤,标记为“否”。
如果该算法学会了如何高精度地识别肿瘤,你就会明白为什么它可能在医疗环境中成为一个有用的工具——电脑可以通过快速分析x射线图像来节省医生的时间。
假设有语言学研究者在研究语言的语法结构。他们有一堆誊写的演讲的文本文件想要分析。他们想教计算机识别句子中的词性,比如形容词、主语和动词。
音乐识别
假设你正在编写一个程序,该程序根据用户的音乐偏好向他们推荐新音乐。用户从歌曲列表中选择自己喜欢的歌曲,程序就会显示他们可能喜欢的新歌。
在这种情况下,输入的训练数据是什么?标签是什么?
输入数据将是用户选择的他们喜欢的歌曲,这可以标记为“喜欢”,而用户没有从列表中选择的歌曲标记为“不喜欢”。
质量控制
假设你在一家电脑处理器工厂工作。当加工商准备包装和运输时,你必须进行质量检查,以确保没有加工商被损坏。描述你如何使用机器学习和分类让电脑帮你做这项工作。
你可以将一台计算机连接到一台相机上,在处理器出厂之前,相机就会为处理器拍照。计算机将运行一种算法,将处理器划分为已损坏或未损坏。您可以使用训练集来教这个算法确定哪些处理器被损坏,这将是有缺陷处理器的图像和功能处理器的图像。
分类算法
选择正确的分类算法非常重要。执行分类的算法称为分类器.分类器算法应该是快速的,准确的,有时,最小化它需要的训练数据量。一般来说,一组数据的参数越多,算法的训练集就必须越大。不同的分类算法从实例中学习模式的方式基本不同。[1]
更正式地说,分类算法映射观察结果 一个概念/类/标签 .
很多时候,分类算法会以a的形式接收数据特征向量它基本上是一个向量,包含与每个数据对象相关的各种特征的数字描述。例如,如果算法处理将动物图像分类(例如,基于动物的类型),特征向量可能包括图像中的像素、颜色等信息。
以下是一些常用的分类算法和技术:
线性回归
一种常见而简单的分类方法是线性回归.
线性回归是一种用来模拟观测变量之间关系的技术。简单线性回归背后的想法是将两个变量的观察值“拟合”成它们之间的线性关系。图形化的任务是画出与点“最拟合”或“最接近”的线 在哪里 和 是两个变量的观测值,这两个变量之间是线性相关的。
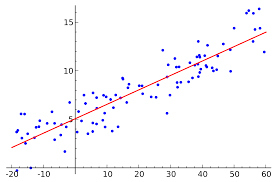 变量之间最合适的线性关系
和
.[2]
变量之间最合适的线性关系
和
.[2]
以下哪一行,H1, H2和H3,代表最差的分类器算法?(分类器算法识别并标记数据,并根据结果将其放置在线的一侧或另一侧)。
H3和H2在这个图中没有误差——所有实心圆都在直线的一边,所有空心圆都在直线的另一边。另一方面,H1把实心圆和空心圆组合在一起,这是一个很差的分类器。

感知器
一个感知器是一种用于生成二进制分类器的算法。即二进制分类算法需要输入数据,以及它们的分类和输出一行,单独的一个类的数据从其他数据:数据点线的一侧的一个类和数据点在另一边。二进制分类数据是指标签上有这样或那样的东西的数据,比如“是”或“不是”;1或0;等。
感知器算法返回值 和 这样,线一边的数据点属于一类,线另一边的数据点属于另一类。在数学上,值 和 被二进制分类器以下列方式使用。如果 ,分类器返回1;否则,返回0。注意,1表示一个类的成员关系,0表示另一个类的成员关系。使用AND操作符可以更清楚地看到这一点,为方便起见,下面复制了该操作符。
 两个数之间的与运算。一个红点代表一个类(
和
),蓝点表示另一个类(
和
).这条线是感知器算法的结果,它将一类数据点与另一类数据点分开。
两个数之间的与运算。一个红点代表一个类(
和
),蓝点表示另一个类(
和
).这条线是感知器算法的结果,它将一类数据点与另一类数据点分开。
感知器算法是二值分类中最常用的机器学习算法之一。一些使用感知器的机器学习任务包括确定性别、疾病的低风险与高风险以及病毒检测。
朴素贝叶斯分类器
朴素贝叶斯分类器是概率分类器具有较强的独立假设之间的特性。不像许多其他分类器,它们假设,对于一个给定的类,将有一些相关在特征之间,朴素贝叶斯明确地将特征建模为有条件的独立考虑到类。
由于独立假设,朴素贝叶斯分类器具有高度可扩展性,可以在有限的训练数据下快速学习使用高维(许多参数)特征。这对于许多真实世界的数据集非常有用,在这些数据集中,每一段数据的特征数量相对较少,例如语音、文本和图像数据。
决策树
另一种分类方法是用决策树.
其他类型的分类算法包括支持向量机(支持向量机),贝叶斯,逻辑回归.假设您有以下篮球运动员的训练数据集,其中包括关于他们拥有什么颜色的球衣、他们在哪个位置打球以及他们是否受伤的信息。训练集根据球员是否能够为a队效力进行标记。
人 球衣颜色 进攻还是防守 受伤吗? 他们会为A队效力吗? 约翰 蓝色的 进攻 没有 是的 史蒂夫 红色的 进攻 没有 没有 莎拉 蓝色的 国防 没有 是的 瑞秋 蓝色的 进攻 是的 没有 理查德。 红色的 国防 没有 没有 亚历克斯 红色的 国防 是的 没有 劳伦 蓝色的 进攻 没有 是的 卡罗 蓝色的 国防 没有 是的 运动员是否可以为a队效力的规则是什么?
他们必须有一件蓝色的球衣,而且不会受伤。要使用决策树对该数据进行分类,请选择一个规则来开始树。
这里我们将使用“jersey color”作为根节点。
接下来,我们将包含一个节点来区分受伤和未受伤的玩家。


在输入数据中使用统计数据
分类算法通常包括统计数据数据。
比方说,一家公司正在尝试编写一款软件,它可以将一本书的全文作为输入。根据某些单词出现的频率,该程序将决定这本书属于哪种体裁。也许,如果“侦探”这个词经常出现,程序就会给这本书贴上“神秘”的标签。如果书中多次包含“魔法”或“巫师”这个词,也许软件应该将书标为“幻想”。等等。(在本例中,这些书的语言是英语)。错误假设电脑程序检查每本书,记录每个单词出现的次数。算法可能会发现,在所有体裁中,单词“The”、“is”、“and”、“I”和其他非常常见的英语单词出现的频率大致相同。根据这些词的频率对小说进行分类可能不会有太大帮助。然而,如果算法注意到某个特定的词汇子集在科幻小说和幻想小说中出现的频率高于在悬疑小说或非虚构小说中出现的频率,那么该算法就可以利用这一信息对未来的图书实例进行排序。
在上面的篮球队例子中,决定一名球员是否会为a队效力的规则非常简单,只需要考虑两个二进制数据点。以书籍类型为例,如果历史小说的主题与一个著名的未解决的犯罪有关,那么它可能会多次使用“detective”这个词。机器学习算法有可能将这部小说归类为推理小说。这就是所谓的错误.很多时候,可以通过给算法提供更多的训练实例来减少误差。然而,完全消除错误是非常困难的,所以一般来说,一个好的分类算法将具有较低的误差出错率越好。
结论
另请参阅
参考文献
- Schurmann, j .(1996)。模式分类.约翰威利,儿子Inc . .
- Sewaqu。线性回归.2010年11月5日,从https://en.wikipedia.org/wiki/Least_squares#/media/File:Linear_regression.svg
- Z。支持向量机分离超平面(SVG).svg.2016年7月18日,从https://en.wikipedia.org/wiki/File Svm_separating_hyperplanes_ (SVG) .
.svg){kind=link}